Jak sztuczna inteligencja może pomóc w kuchni?

Na zakończenie Bootcampu Kodołamacz Data Science, którego jestem absolwentem, każdy z uczestników musiał wykonać samodzielnie projekt pokazujący umiejętności zdobyte podczas kursu.
Z jednej strony miał to być test zdobytej wiedzy, z drugiej zaś (i to przede wszystkim) bodziec do dodatkowej nauki i zdobywania praktyki w pisaniu kodu. Ponieważ najbardziej interesującą dla mnie częścią zajęć był Deep Learning oraz przetwarzanie obrazu, postanowiłem zmierzyć się problemem z tego obszaru. Bardzo chciałem, aby wykonany przeze mnie projekt nie ograniczał się do automatycznego rozdzielania wymieszanych zdjęć psów i kotów na dwa foldery, ale mógł mieć jakieś bardziej praktyczne zastosowanie. Idąc tym tokiem przyszła mi do głowy aplikacja, która na podstawie zdjęć produktów jakie mamy w kuchni podpowie nam kulinarne przepisy (chciałbym podkreślić, że w moim pomyśle nie inspirowałem się żadną działającą tak aplikacją, jednocześnie nie mam pewności, czy takowa nie istnieje już w użyciu). Metody sztucznej inteligencji miały więc pomóc w rozwiązaniu często spotykanego problemu “co mógłbym zrobić z tego co mam w lodówce?”. Nie znam nikogo, kto choć raz w życiu nie stanął z burczącym brzuchem przed takim dylematem.
Marchewka czy banan - jak działają sieci neuronowe?
W założeniu działanie programu było proste. Robimy zdjęcie produktów, program rozpoznaje co jest na zdjęciu i na podstawie tak przygotowanej listy wyszukuje nam dostępne przepisy. Dodając do tego na przykład informację o tym, czy mamy ochotę bardziej na deser, sałatkę czy może danie vege, dostajemy pomysł na wymarzoną kolację.
Moduł rozpoznający produkty spożywcze byłby więc nieodzowną częścią programu, bez którego nie mógłby on działać tak jak to zostało zaplanowane. Wykonanie tego elementu zostało tematem mojego projektu zaliczeniowego. W Data Science problem taki jest nazywany klasyfikacją wieloklasową. W ogólności rozwiązanie sprowadza się do stworzenia algorytmu, który będzie rozpoznawał, do której z wcześniej zdefiniowanych grup należy obraz widoczny na zdjęciu. Do tego celu wykorzystywane są głębokie sieci neuronowe. Podejście polega na tym, że sieć neuronowa uczy się rozpoznawać, na podstawie zbioru zdjęć, co przedstawia dany obraz. Zbiór zdjęć uczących jest podzielony na klasy zgodnie z rodzajami obiektów (w naszym przypadku rodzajów produktów). W trakcie uczenia sieć dostraja siły połączeń między neuronami tak, aby predykcje były jak najtrafniejsze. Formalnie, sieć optymalizuje w trakcie uczenia tzw. funkcję kosztu (ang. loss function), która mierzy jak bardzo sieć się myli.
Przybliżmy zasadę działania sieci neuronowych na przykładzie. Załóżmy, że nasz zbiór składa się z 3 klas obrazów: rowerów, kajaków i hulajnóg. Zestawy zdjęć przedstawiające te środki transportu wykorzystuje się do trenowania sieci neuronowej. Wytrenowana sieć może dokonywać predykcji na dowolnym, nowym dla niej obrazie, co sprowadza się do obliczenia prawdopodobieństwa z jakim reprezentuje on każdą z klas. Klasa, która zostanie wskazana jako najbardziej prawdopodobna, jest wynikiem predykcji. Zwróćmy uwagę, że sieć zawsze wytypuje jakąś klasę, nawet jeśli obraz nie pasuje do żadnej z nich. Jeżeli na wejściu podamy zdjęcie bicykla (taki śmieszny starodawny rower z duży przednim i malutkim małym kołem) to pomimo, że w zbiorze obrazów, na których sieć się uczyła nie było takiego “antyka”, jest duża szansa, że zostanie on zakwalifikowany do rowerów, co możemy uznać za rozsądne. Jeżeli jednak na wejściu podamy zdjęcie deskorolki, to algorytm wyliczy nam prawdopodobieństwa, że jest to rower/kajak/hulajnoga i nie powie nam, że ten obraz nie pasuje do żadnej kategorii. Może się więc okazać, że nasza deskorolka zostanie zakwalifikowana jako np. hulajnoga.
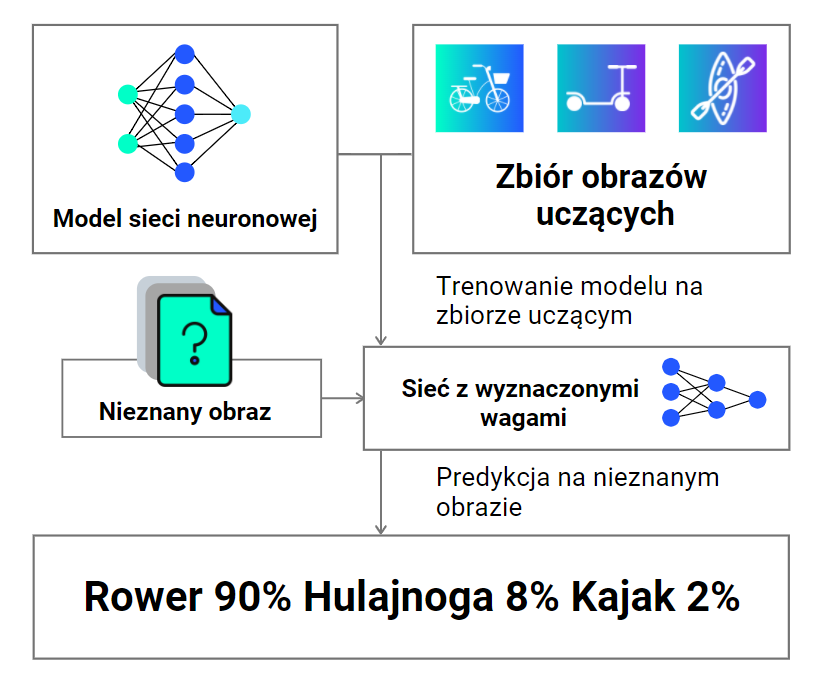 Schemat zastosowania sieci neuronowych
Schemat zastosowania sieci neuronowych
Sama sieć neuronowa zbudowana jest z neuronów ułożonych w warstwach. W najprostszej wersji, sieć składa się z trzech warstw: wejściowej, ukrytej i wyjściowej. Pierwsza warstwa służy wprowadzeniu danych do sieci, w warstwie ukrytej odbywa się przetwarzanie informacji otrzymanych na wejściu, natomiast warstwa wyjściowa zwraca werdykt sieci - wyliczenia, które wskazują ja bardzo rozważany obiekt pasuje do poszczególnych kategorii. Natomiast stosowanych modelach warstw może być dużo więcej. Ilość neuronów w warstwach ukrytych ukrytych jest definiowana przez programistę - w praktyce testuje się różne warianty w celu znalezienia najlepszej struktury sieci, natomiast warstwy wejściowa i wyjściowa zawierają tyle neuronów ile mamy informacji wejściowych i ile klas chcemy rozpoznawać.
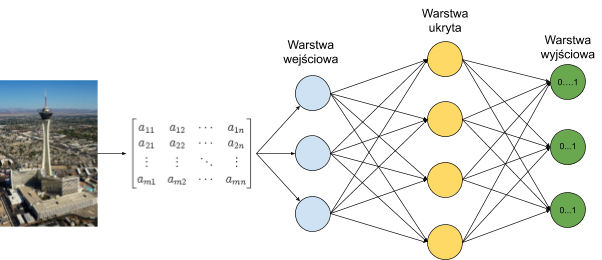 Predykcja siecią neuronową 3-warstwową
Predykcja siecią neuronową 3-warstwową
Sam neuron natomiast jest czymś w rodzaju prostej jednostki obliczeniowej. Na wejściu otrzymuje on wartości wyjściowe ze wszystkich neuronów warstwy poprzedzającej (za wyjątkiem neuronów w warstwie wejściowej), które to wartości po poddaniu ich operacjom matematycznym, oraz działaniu funkcji aktywacji neuronu, są przekazywane do kolejnej warstwy.
Gotuj z AI
Przygotowanie rozwiązania problemu klasyfikacji wieloklasowej z użyciem sieci neuronowych wymagało wykonania następujących kroków:
- stworzenie lub znalezienie zbioru uczącego zawierającego obrazy warzyw i owoców;
- zaprojektowanie i oprogramowanie pre-processingu danych wejściowych;
- zaprojektowanie i wytrenowanie modelu z wykorzystaniem przygotowanych danych;
- testy, testy, poprawki.. i jeszcze raz testy i poprawki;
- zaimplementowanie gotowego modelu do modułu klasyfikującego produkty na zdjęciach.
Do wykonania zadania postanowiłem zastosować głębokie uczenie konwolucyjnych sieci neuronowych (ang.CNN - Convolutional Neural Network). Konwolucyjna sieć neuronowa jest siecią neuronową mającą zastosowanie w przetwarzaniu obrazów. W kolejnych swoich warstwach CNN dokonuje ekstrakcji cech obrazów oraz agregacji informacji.
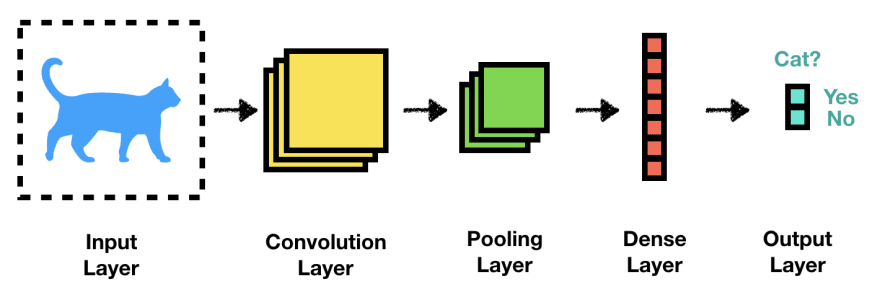 Warstwy sieci konwolucyjnej, źródło www.towardsdatascience.com
Warstwy sieci konwolucyjnej, źródło www.towardsdatascience.com
Konwolucja, lub też splot macierzy, jest działaniem na 2 macierzach w wyniku którego powstaje nowa macierz. Przedstawia to poniższa grafika. Jedna z macierzy (niebieska) reprezentuje obraz, a druga (zielona) to filtr, którego wielkość jest jednym z parametrów warstwy sieci. Na poniższym przykładzie, w wyniku operacji splotu powstaje macierz 3x3 pokazana po prawej stronie grafiki:
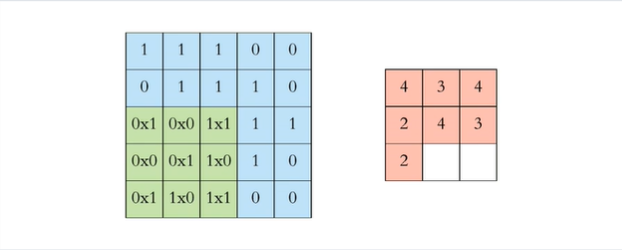 Konwolucja, źródło: www.freecodecamp.org
Konwolucja, źródło: www.freecodecamp.org
Agregacja informacji (pooling) służy redukcji rozmiaru macierzy. Polega na przechodzeniu oknem o zdefiniowanej wielkości (np 2x2) po kolejnych fragmentach macierzy i wyborze z każdego okna wartości spełniającej określony warunek. Załóżmy, że mamy macierz 4x4 na której operujemy oknem 2x2, które przesuwamy kolejno co 2 kolumny i 2 wiersze. Dla każdego kolejnego fragmentu próbkujemy najwyższą wartość. Wynikową macierzą będzie macierz 2x2 składająca się z próbkowanych wcześniej wartości. Możemy przedstawić to za pomocą grafiki:
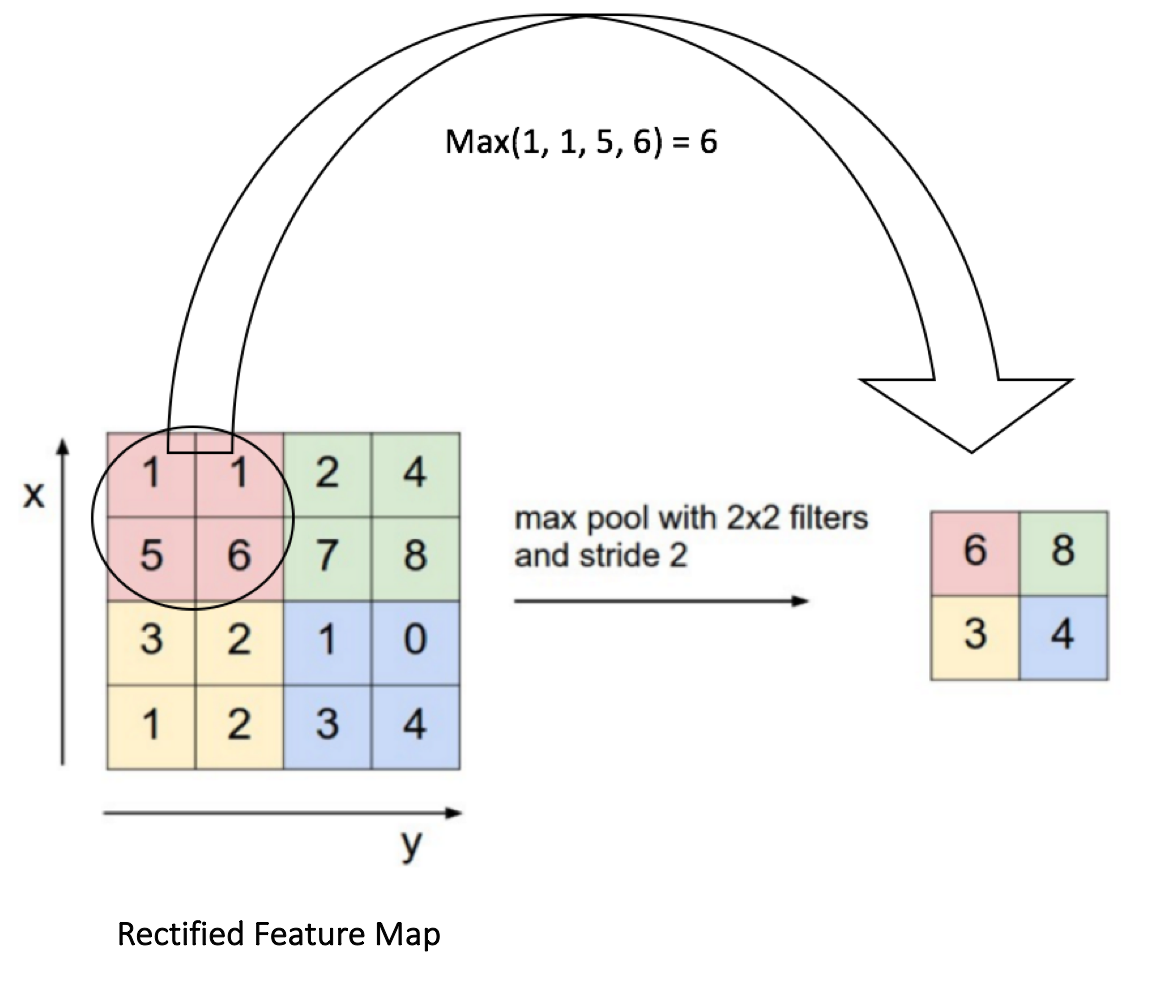 Pooling, źródło: www.freecodecamp.org
Pooling, źródło: www.freecodecamp.org
Każda kolejna warstwa sieci konwolucyjnej wykonuje po jednej operacji. W praktyce działanie konwolucyjnej sieć neuronowej naśladuje rozpoznawanie obrazu przez człowieka. Działania kolejnych filtrów w kolejnych warstwach uwydatniają cechy grafiki. Przechodząc od szczegółu (krawędzie, kształty) do ogółu (twarz, postać) sieć krok po kroku modeluje obiekt. Jednocześnie w kolejnych warstwach, sieć uczy się pewnych aspektów danych i ,,rozumienia” grafiki wejściowej.
 Przetwarzanie grafiki w kolejnych warstwach sieci konwolucyjnej, źródło www.mcs.csueastbay.edu
Przetwarzanie grafiki w kolejnych warstwach sieci konwolucyjnej, źródło www.mcs.csueastbay.edu
Powyższy opis jest oczywiście pewnym uproszczeniem pracy konwolucyjnej sieci neuronowej, jednak w zupełności wystarczy do wyjaśnienia jak to działa.
Czym karmimy model?
Stworzenie właściwego zestawu obrazów, który pozwala wytrenować sieć jest niezwykle czasochłonnym zajęciem. Możemy to przedstawić na przykładzie jabłka. Aby sieć nauczyła się je poprawnie rozpoznawać na różnych obrazkach, nasz zestaw zdjęć powinien zawierać jabłka o wielu możliwych kształtach, kolorach, pod różnymi kątami, różnie oświetlone. Jabłko może być jędrne i błyszczące, ale też nadgniłe i pomarszczone. Mamy jabłka czerwone, zielone, żółte i wielokolorowe. Są z ogonkiem i listkiem, ale czasem trafią się bez żadnego z tych elementów. Jeśli rozpatrujemy jabłko w kuchni, to może się okazać, że dysponujemy owocem przekrojonym na dwie połowy i właśnie z tego chcielibyśmy coś przyrządzić. Nie jest to tak trywialny problem jak początkowo może się wydawać. Dlatego dobrym rozwiązaniem jest korzystanie z gotowych zestawów obrazków, które będą uwzględniały jak najwięcej przypadków. W ten właśnie sposób postąpiłem realizując swoją pracę. Do uczenia sieci wykorzystałem opublikowany w Internecie zbiór zdjęć, który opisany jest w pracy: Horea Muresan, Mihai Oltean, Fruit recognition from images using deep learning, Acta Univ. Sapientiae, Informatica Vol. 10, Issue 1, pp. 26-42, 2018. Zbiór ten przygotowany został z dużą starannością i składa się z fotografii przedstawiających produkty w różnorodnym stanie, pod różnymi kątami, z oczyszczonym tłem. Posiada więc większość cech jakimi powinien charakteryzować się właściwy dataset.
 Grafika z datasetu ‘Fruit 360’, rozm. 100x100 px.
Grafika z datasetu ‘Fruit 360’, rozm. 100x100 px.
Niestety zbiór posiada też wady. Składa się z dużej ilości klas (114), ale na każdą klasę przypada jedynie ok. 450 fotografii. Zdecydowanie nie jest to imponująca liczba. Przy głębokim uczeniu sieci neuronowych może to nie wystarczyć do skutecznego nauczenia sieci. Z pomocą przychodzi tutaj augmentacja danych. Jest to zestaw metod, które umożliwiają w sposób sztuczny zwiększyć ilościowo oraz jakościowo dataset. Pisząc “jakościowo” mam na myśli różnorodność obrazów.
Przyrządzamy dane wejściowe
Przy tworzeniu mojego modułu skorzystałem z pythonowego pakietu Keras. Jest to bardzo wygodne API przeznaczone do pracy z sieciami neuronowymi. Do dalszej pracy postanowiłem wykorzystać 11 spośród dostępnych w datasecie klas. Wykonana przeze mnie augmentacja danych polegała zastosowaniu pewnych transformacji obrazów. Wykorzystałam tutaj zdefiniowaną w Kerasie klasę ImageDataGenerator. Obiekt klasy ImageDataGenerator zawiera parametry określające jakim operacjom zostanie poddany przekazany do niego obraz. Może to być obrót obrazu o kąt, odbicie, rozjaśnienie lub ściemnienie itp. Przy inicjalizacji obiektu ImageDataGenerator określa się zakres wybranych parametrów, a ich wartość dla każdego kolejnego obrazu jest określana losowo z podanego przy inicjalizacji zakresu. Wywołany przeze mnie obiekt miał następujące parametry:

Każdy obraz ze zbioru uczącego był obrócony w zakresie 0-45°, odbity wertykalnie/horyzontalnie oraz zmieniono mu jasność w zakresie 70-100% (przy czym 100% oznacza brak zmiany). Widzimy także parametr rescale=1./255. Jest to nic innego jak standaryzacja wartości natężenia koloru. Dla użytej palety RGB natężenie zawiera się w przedziale 1-255. Sieci neuronowe zdecydowanie lepiej radzą sobie z liczbami z przedziału 0-1, stąd taka operacja.
W drugim kroku definiujemy schemat przepływu danych. Zbiór uczący został podzielony na foldery - każdy folder zawierał obrazy jednej klasy. Aby wszystko to połączyć w całość zastosowałem metodę flow_from_directory. Wywołujemy ją na obiekcie klasy ImageDataGenerator (w tym przypadku train_idg). Metoda po podaniu kilku parametrów technicznych generuje obrazy poddane augmentacji, przygotowane do przekazania sieci neuronowej.

W powyższym kodzie na obiekcie wywołujemy metodę z kilkoma parametrami. train_path jest zmienną zawierającą ścieżkę do folderów ze zdjęciami, target_size określa rozmiar (wysokość i szerokość) obrazów wejściowych, class_mode to parametr definiujący jakiego rodzaju predykcję będziemy wykonywać. Categorical oznacza, że będzie to klasyfikacja wieloklasowa.
Modelowanie i trening sieci neuronowej
Kolejnym etapem było zaprojektowanie modelu sieci neuronowej. W bibliotece keras w prosty sposób możemy definiować swoją sieć warstwa po warstwie. Poniższy kod definiuje strukturę modelu, który po wytrenowaniu okazał się być najskuteczniejszy.

Sequential() jest modelem stosu kolejnych warstw sieci. Patrząc od góry mamy najpierw warstwę wejściową Conv2D(). Pierwszym parametrem tej warstwy jest liczba filtrów, kolejnymi: rozmiar filtra, przesunięcie filtra, rodzaj funkcji aktywacji. Ostatnim parametrem jest input_size. Określmy tu rozmiar obrazka wejściowego (taki sam jak we flow_from_directory) oraz liczbę macierzy z jakich składa się grafika. W moim przypadku liczba 3 odpowiada trzem kanałom RGB.
Kolejną warstwą jest warstwa pooling, potem znów konwolucja itd. aż do warstw Flatten() i Dense(), które są nowością w modelu. Flatten() ‘spłaszcza’ macierze jakie powstały w wyniku kolejnych operacji do jednego wymiaru, czyli wektora. Ostatnia warstwa Dense() natomiast jest warstwą wyjściową. Musi składać się z tylu neuronów, ile klas rozpoznajemy w naszym problemie. Ostatnia część kodu wywołująca funkcję model.compile kompiluje przygotowany model, definiując przy okazji rodzaj funkcji kosztu oraz metodę jej optymalizacji, czyli algorytm uczący.
Tak przygotowane modele poddałem treningowi, wykorzystując kolejną funkcję fit_generator.

Dokładny opis wszystkich zdefiniowanych parametrów zawiera dokumentacja modułu keras, dostępna na stronie https://keras.io/.
Co udało się z tego przyrządzić?
Podczas tworzenia mojego projektu napotkałem szereg problemów. Napisanie właściwego preprocessingu danych, tworzenie modeli sieci, wizualizacja wyników, oraz implementacja finalnego rozwiązania - na każdym z tych etapów pojawiały się jakieś problemy, które jednak okazywały się rozwiązywalne. Dużym ułatwieniem w pracy były wszystkie pakiety Pythonowe, które umożliwiają zastosowanie gotowych funkcji. Często jednak właściwa parametryzacja tych narzędzi okazywała się pewnym wyzwaniem i wymagała poświęcenia czasu na pracę z dokumentacją.
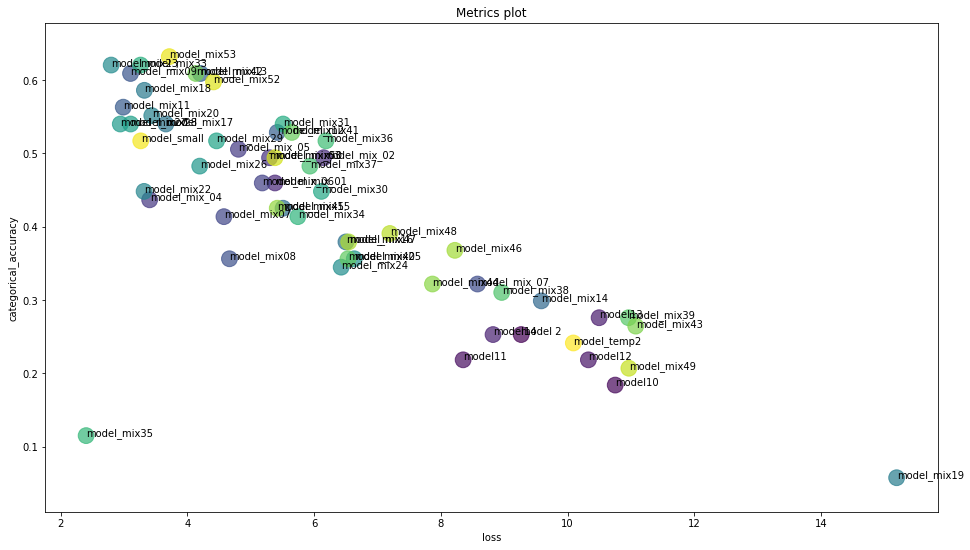 Wykres trafności predykcji (OY) względem wartości funkcji kosztu (OX) dla testowanych modeli
Wykres trafności predykcji (OY) względem wartości funkcji kosztu (OX) dla testowanych modeli
Na powyższym wykresie widzimy wszystkie sprawdzone przeze mnie modele. Pokazuje to ilość prób i eksperymentów jakie podjąłem. Na wykresie oś OX reprezentuje funkcję kosztu, OY to dokładność klasyfikacji. Widzimy, że spadek wartości funkcji kosztu odpowiada wzrostowi dokładności predykcji. Próbowałem zarówno prostych 4-5 warstwowych modeli jak i dużych, kilkunasto warstwowych, uczących się dobre kilkanaście godzin. Jak to w życiu - najlepsze rozwiązanie jakie udało mi się znaleźć leżało gdzieś pośrodku. Czym kierować się przy wyborze tego, który finalnie wykorzystamy? Z praktycznego punktu widzenia, niewątpliwie kluczowa jest trafność predykcji.
Wytrenowane przeze mnie modele pozwalały na predykcję w obrębie 11 różnych klas. Poniżej ich lista:
- {
Apple Granny Smith: 0 Apple Red: 1Avokado: 2Banana: 3Kiwi: 4Lemon: 5Onion White: 6Oragne: 7Potato White: 8Tomato: 9Walnut: 10}
Dla sprawdzenia jak działa przykładowa predykcja na pobranych z sieci obrazach owoców i warzyw przeprowadziłem kilka testów, wykorzystując zdefiniowaną przeze mnie funkcję prediction(). Oto wyniki:
Pierwszy testowy obrazek:

Wynik:
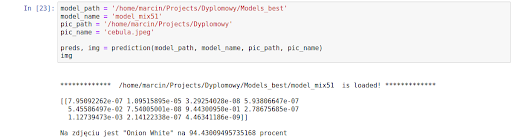
Sieć wygenerowała tablicę 11 prawdopodobieństw. Najwyższe z nich (o wartości 0.944) jest dla klasy nr 6, której odpowiada Onion White. Potwierdza to także wypisany pod tablicą komunikat. Dobry wynik!
Drugi testowy obrazek:

Wynik:
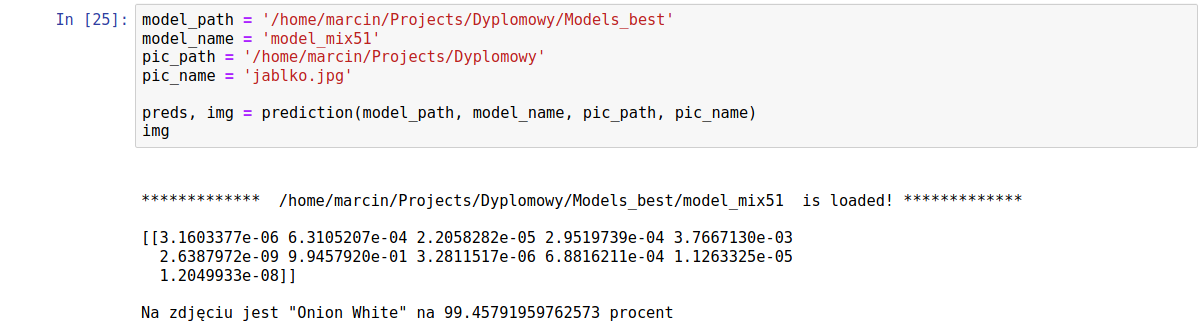
Kolejna tablica prawdopodobieństw i… podobnie jak w pierwszym przykładzie najwyższe z nich ma klasa nr 6, czyli biała cebula. To jest niestety zły wynik.
Trzeci testowy obrazek:

Wynik:
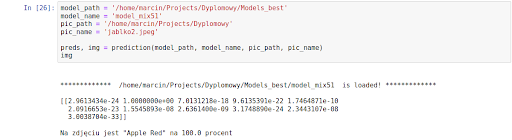
Dla trzeciego przykładu, a zarazem drugiego jabłka, najwyższe prawdopodobieństwo przypisano klasie nr 1, co odpowiada ‘Apple Red’. Dobry wynik!
Na powyższych 3 przykładach widzimy co jest rezultatem predykcji konwolucyjnej sieci neuronowej. Dwa z obrazów zostały rozpoznane poprawnie, trzeci natomiast błędnie.
Kod jaki napisałem przy projekcie, dostępny jest na platformie GitHub: https://github.com/Ernest101/food-image-recognition
Artykuł powstał na podstawie projektu Absolwenta kursu Data Science PRO.



