Fałszywa rzeczywistość, czy prawdziwa abstrakcja?

Aby pokazać jak fantastyczny i intrygujący jest powyższy temat oraz tempo jego rozwoju, spójrz na poniższe obrazy:
 Źródło: https://arxiv.org/abs/1809.11096
Źródło: https://arxiv.org/abs/1809.11096
Obrazy, które właśnie zobaczyłeś, zostały całkowicie wygenerowane z szumu. Są unikatowe, niepowtarzalne i jednocześnie w 100 % fałszywe.
GAN (Generative Adversarial Networks- generatywne sieci współzawodniczące) to potężna klasa sieci neuronowych wykorzystywana w nauczaniu bez nadzoru. Odniosła ona ogromny sukces, odkąd została wprowadzona w 2014 roku przez Ian J. Goodfellow i współautorów w artykule „Generative Adversarial Nets”. Według słynnego pioniera, w dziedzinie sztucznej inteligencji zwanego również jednym z trzech „Ojców Chrzestnych” uczenia głębokiego Yanna LeCuna, GANy są „najciekawszym pomysłem w ciągu ostatnich dziesięciu lat w uczeniu maszynowym”.
Czym jest GAN i co sprawia, że są tak interesujące?
Generative Adversarial Networks to modele generatywne wykorzystujące metody głębokiego uczenia, w szczególności takie jak splotowe sieci neuronowe. Modelowanie generatywne to dziedzina uczenia maszynowego zajmująca się algorytmami, które mają za zadanie tworzyć obiekty wiernie odzwierciedlające obiekty rzeczywiste (np. obrazy). Od strony metodologicznej, jest to problem uczenia nienadzorowanego, w którym algorytm w sposób w pełni zautomatyzowany wykrywa i uczy się wzorców występujących w danych, na podstawie których generuje nowe przykłady.
Sieci GAN są sprytnym sposobem szkolenia modelu generatywnego poprzez zdefiniowanie problemu jako nadzorowanego problemu uczenia się za pomocą dwóch podmodeli:
- generatora, który trenujemy w celu generowania nowych przykładów;
- dyskryminatora, który próbuje rozpoznać przykłady jako rzeczywiste lub fałszywe.
Oba modele są wspólnie trenowane w grze o sumie zerowej, przeciwnej, dopóki dyskryminatora nie będzie w stanie rozróżnić obiektów prawdziwych od sztucznych, co będzie oznaczało, że model generatora wytwarza wiarygodne przykłady.
Sieci GAN są niesamowicie szybko rozwijającą dziedziną, która pozwoli na generowanie realistycznych przykładów, które mogą zostać wykorzystane w różnych obszarach problemowych. Przykładowe implementacje sieci GAN możemy zastosować do:
- generowania zdjęć ludzkich twarzy
- generowania realistycznych zdjęć
- generowanie postaci z kreskówek
- transformowania obrazu
- tłumaczenia tekstu na obraz
- generowania nowych ludzkich postawy
- edycji zdjęć
- malowania zdjęć
- prognozy video
- generowania obiektów 3D
Popularnym przykładem wykorzystania takich mechanizmów są aplikacje pozwalające na stworzenie reprezentatywnej wersji nas samych z dodatkiem różnych cech (broda, postarzenie, odmłodzenie itp.). Niewyobrażalne tempo w odnośnie jakości GAN-ów możemy zobaczyć poniżej.
 Postęp GAN w generowaniu twarzy na przestrzeni czterech i pół roku. Źródło: https://arxiv.org/abs/1406.2661, https://arxiv.org/abs/1511.06434, https://arxiv.org/abs/1606.07536, https://arxiv.org/abs/1710.10196, https://arxiv.org/abs/1812.04948
Postęp GAN w generowaniu twarzy na przestrzeni czterech i pół roku. Źródło: https://arxiv.org/abs/1406.2661, https://arxiv.org/abs/1511.06434, https://arxiv.org/abs/1606.07536, https://arxiv.org/abs/1710.10196, https://arxiv.org/abs/1812.04948
Jak to działa?
Wyjaśnijmy to na przykładzie obrazów. Sieci GAN składają się z dwóch odrębnych modeli: generatora i dyskryminatora. Zadaniem generatora jest tworzenie fałszywych obrazów, które będą wyglądać jak obrazy rzeczywiste, na których sieć jest uczona. Zadaniem dyskryminatora jest analiza” obrazu wyjściowego i stwierdzenie czy jest on prawdziwy. Podczas trenowania generator uczy się oszukiwać dyskryminatora, generując coraz to lepsze podróbki, podczas gdy dyskryminator uczy się rozpoznawać prawdziwości obiektów. Trenowanie można zobrazować za pomocą poniższego obrazka:
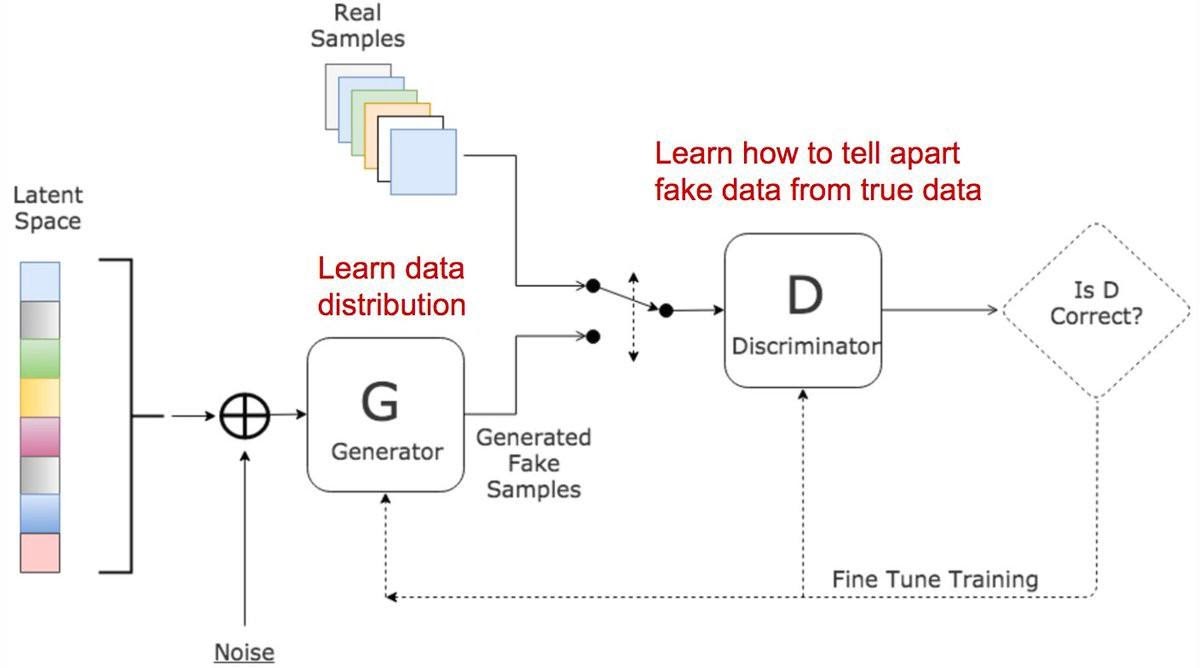
Można porównać to do sytuacji, gdy oszust próbuje sprzedać obraz, a specjalista od dzieł sztuki musi stwierdzić czy jest to oryginał, czy podróbka. Równowaga tej gry następuje wtedy, gdy generator tworzy doskonałe podróbki, które wyglądają, jakby pochodziły bezpośrednio z danych treningowych, a dyskryminator (nasz specjalista) zawsze wskazuje, że wyjściowy produkt jest prawdziwy lub fałszywy z jednakowym prawdopodobieństwem (50%). W teorii gier model GAN jest zbieżny, gdy generator i dyskryminator osiągają równowagę Nasha. Jest to optymalny punkt dla równania min-max poniżej:
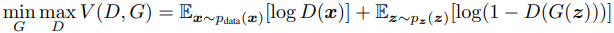
Przykładowe użycie sieci DCGAN na przykładzie generowania obrazów animowanych w języku Python z wykorzystaniem biblioteki Keras
Zbiór danych treningowych pochodzi z strony Kaggle i przedstawia zbiór 21551 kolorowych obrazków twarzy animowanych o rozmiarach 64x64 piksela. Pierwszym krokiem do opracowania kodu jest załadowanie obrazu oraz przekształcenie go do postaci wektorowej oraz normalizacja tak, aby wartości mieściły się w przedziale [-1,1].

```def norm_img(img): images = numpy.array(img) images = (images / 127.5) - 1 images = images.astype(‘float32’) return images
```def get_data():
all_images = []
for index, filename in enumerate(glob.glob(folder_z_obrazami)):
image = imageio.imread(filename, as_gray=False, pilmode='RGB')
all_images.append(image)
return norm_img(all_images)
Następnie bierzemy się do zbudowania modeli.
Model dyskryminatora przyjmuje jako dane wejściowe jeden kolorowy obraz rozmiaru 64x64 piksela i zwraca na końcu binarną predykcję, mówiącą o tym czy obraz jest prawdziwy (klasa 1) czy też fałszywy (klasa 0). Jest on zaimplementowany jako skromna splotowa sieć neuronowa z wykorzystaniem funkcji aktywacji LeakyReLU o nachyleniu 0.2, użyciu kroku 2x2 do próbkowania (stride), optymalizatora Adam z szybkością uczenia wynoszącą 0.0002 oraz pędem 0.5 oraz funkcji aktywacji sigmoid w warstwie wyjściowej.
Poniższa funkcja make_discriminator() implementuje to, definiując i kompilując model dyskryminatora oraz zwracając go.
def make_discriminator(noise_shape):
optimizer = Adam(lr=0.0002, beta_1=0.5)
discriminator_input = Input(shape=image_shape)
d = Conv2D(128, 3, padding='same')(discriminator_input)
d = LeakyReLU(0.2)(d)
# downsample to 30x30
d = Conv2D(128, 5, strides=(2,2))(d)
d = LeakyReLU(0.2)(d)
# downsample to 13x13
d = Conv2D(128, 5, strides=(2,2))(d)
d = LeakyReLU(0.2)(d)
# downsample to 5x5
d = Conv2D(128, 5, strides=(2,2))(d)
d = LeakyReLU(0.2)(d)
# Flatten the input image
d = Flatten()(d)
d = Dropout(0.4)(d)
d = Dense(1, activation='sigmoid')(d)
discriminator_model = Model(discriminator_input, d) discriminator_model.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
discriminator_model.summary()
return discriminator_model
Model generatora przyjmuje na wejściu punkt z przestrzeni utajonej i generuje pojedynczy kolorowy obraz rozmiaru 64x64 piksela. Innymi słowy, generator na wejściu otrzymuje zupełnie losowy zestaw liczb, zwany szumem, na podstawie którego wytworzony zostaje obraz.
Nasz generator jest małą splotową siecią neuronową z jedną warstwą gęstą na wejściu. Wprowadzony do modelu szum jest przekształcany w obraz o niskiej rozdzielczości 16x16. Następnie poddany jest dwukrotnie próbkowaniu podwajając za każdym razem swój rozmiar dzięki warstwie dekonwolucji (Conv2DTranspose). W modelu wykorzystywana jest funkcja aktywacji LeakyReLU o nachyleniu 0.2, krok próbkowania 2x2 do podwojenia rozmiaru obrazu oraz funkcja aktywacji tangens hiperboliczny w warstwie wyjściowej.
Poniższa funkcja make_generator() definiuje model generatora. Rozmiar ukrytej przestrzeni, będącej źródłem „punktów startowych” sieci, jest parametryzowany jako argument funkcji.
def make_generator(noise_shape):
generator_input = Input(shape=(noise_shape))
# fully conected layers
g = Dense(128 * 16 * 16)(generator_input)
g = LeakyReLU(0.2)(g)
g = Reshape((16, 16, 128))(g)
g = Conv2D(256, 5, padding='same')(g)
g = LeakyReLU(0.2)(g)
# upsample to 16x16
g = Conv2DTranspose(256, (4,4), strides=(2,2), padding='same')(g)
g = LeakyReLU(0.2)(g)
# upsample to 32x32
g = Conv2DTranspose(256, (4,4), strides=(2,2), padding='same')(g)
g = LeakyReLU(0.2)(g)
# upsample to 64x64
g = Conv2D(256, 5, padding='same')(g)
g = LeakyReLU(0.2)(g)
g = Conv2D(3, 8, activation='tanh', padding='same')(g)
generator_model = Model(generator_input, g)
generator_model.summary()
return generator_model
Możemy zająć się zdefiniowaniem modelu GAN, łączącego w sobie model generatora i dyskryminatora. Pełny model będzie używany do trenowania wag modelu w generatorze, dzięki błędom obliczonym przez model dyskryminatora. W połączonym modelu, który będzie trenował nasz generator, parametry dyskryminatora są utrzymywane na stałym poziomie (discriminator.trainable=False), a sam dyskryminator będzie trenowany jako niezależnie skompilowany model. Jako funkcję straty, którą staramy się minimalizować w procesie trenowania, przyjmujemy entropię. Jest ona miarą różnicy między wyliczonymi przez sieć prawdopodobieństwami a rzeczywistymi wartościami dla binarnych prognoz. Im większa strata, tym nasze prognozy są dalsze od prawdziwych etykiet. Do optymalizacji sieci używamy algorytmu Adam z szybkością uczenia wynoszącą 0.0002 oraz pędem 0.5.
Zaimplementowano to w funkcji make_gan() zdefiniowanej poniżej, przyjmując jako dane wejściowe już zdefiniowane modele generatora i dyskryminatora.
def make_gan(g, d):
optimizer = Adam(lr=0.0002, beta_1=0.5)
generator_input = Input(shape=noise_shape)
gan_input = g(generator_input)
gan_output = d(gan_input)
gan = Model(generator_input, gan_output)
gan.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
gan.summary()
return gan
Teraz możemy przejść do procesu trenowania
Najpierw definiujemy potrzebne zmienne (informacja o kształtach danych, ścieżki)
noise_shape = (1, 1, 100)
image_shape = (64,64,3)
EPOCHS = 10000
batch_size = 128
data_dir = 'D:/DATASET/animefaces/*.*'
save_images_dir = 'D:/projekt_output/Images/'
save_model_dir = 'D:/projekt_output/Model/'
oraz kompilujemy model:
discriminator = make_discriminator(image_shape=image_shape)
generator = make_generator(noise_shape=noise_shape)
discriminator.trainable = False
gan = make_gan(generator, discriminator)
Pętla treningowa rozpoczyna się od momentu otrzymania przez generator losowego wektora jako danych wejściowych. Na jego podstawie będzie generowany obraz. Dyskryminator służy następnie do określania prawdziwości rzeczywistych i fałszywych (wytwarzanych przez generator) obrazów. Stratę oblicza się dla każdego z tych modeli, a gradienty są używane do aktualizacji generatora i dyskryminatora.
Poniższy kod przedstawia implementację procesu trenowania dla zdefiniowanych modeli, zestawu danych i rozmiaru ukrytego wymiaru oraz parametryzując liczbę epok i wielkość batcha. Co 50 epok pętla generuje zestaw obrazków 8x8 z wygenerowanymi twarzami oraz co 500 epok wagi poszczególnych modeli.
for epoch in tqdm(range(EPOCHS)):
idx = np.random.randint(0, X.shape[0], batch_size)
real_data_X = X[idx]
noise = np.random.normal(0, 1, size=(batch_size,) + noise_shape)
fake_data_X = generator.predict(noise)
if (epoch % 50) == 0:
plt.figure(figsize=(8, 8))
gs1 = gs.GridSpec(8, 8)
gs1.update(wspace=0, hspace=0)
random_indices = np.random.choice(fake_data_X.shape[0], 64, replace=False)
for i in range(64):
ax1 = plt.subplot(gs1[i])
ax1.set_aspect('equal')
random_index = random_indices[i]
image = fake_data_X[random_index, :, :, :]
fig = plt.imshow(denorm_img(image))
plt.axis('off')
fig.axes.get_xaxis().set_visible(False)
fig.axes.get_yaxis().set_visible(False)
plt.tight_layout()
plt.savefig(save_images_dir + str(epoch).zfill(5) + "_image.png", bbox_inches='tight', pad_inches=0)
plt.close()
data_X = np.concatenate([real_data_X, fake_data_X])
real_data_Y = np.ones(batch_size) - np.random.random_sample(batch_size) * 0.2
fake_data_Y = np.random.random_sample(batch_size) * 0.2
data_Y = np.concatenate((real_data_Y, fake_data_Y))
discriminator.trainable = True
generator.trainable = False
dis_metrics_real = discriminator.train_on_batch(real_data_X, real_data_Y)
dis_metrics_fake = discriminator.train_on_batch(fake_data_X, fake_data_Y)
discriminator_fake_losses.append(dis_metrics_fake[0])
discriminator_real_losses.append(dis_metrics_real[0])
generator.trainable = True
GAN_X = np.random.normal(0, 1, size=(batch_size,) + noise_shape)
GAN_Y = real_data_Y
discriminator.trainable = False
gan_metrics = gan.train_on_batch(GAN_X, GAN_Y)
if (epoch % 1000) == 0:
print(f"Epoch: {epoch}/{EPOCHS}")
print("Discriminator: real loss: %f fake loss: %f" % (dis_metrics_real[0], dis_metrics_fake[0]))
print("GAN loss: %f" % (gan_metrics[0]))
text_file = open(save_model_dir + "\\training_log.txt", "a")
text_file.write("Epoch: %d Discriminator: real loss: %f fake loss: %f GAN loss: %f\n" % (epoch, dis_metrics_real[0], dis_metrics_fake[0], gan_metrics[0]))
text_file.close()
gan_losses.append(gan_metrics[0])
if ((epoch + 1) % 500) == 0:
discriminator.trainable = True
generator.trainable = True
generator.save(save_model_dir + str(epoch) + "_GENERATOR.hdf5")
discriminator.save(save_model_dir + str(epoch) + "_DISCRIMINATOR.hdf5")
Wyniki
Poniżej możemy spojrzeć na wykres strat modelu.
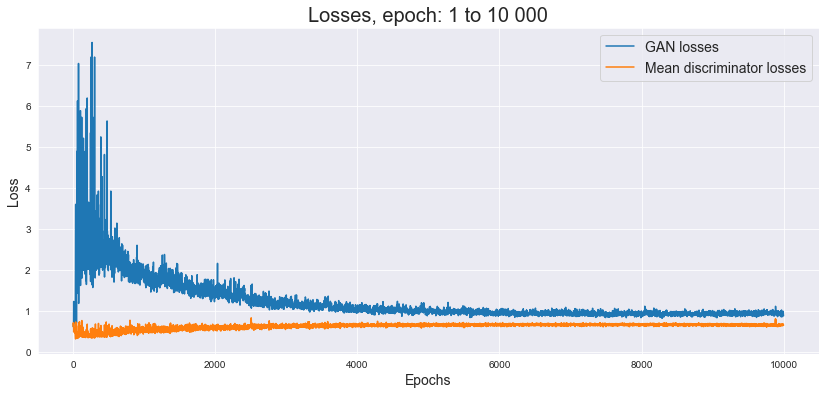
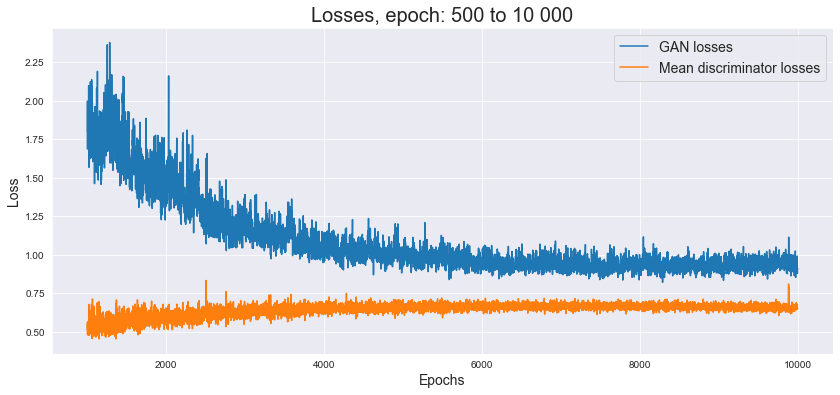
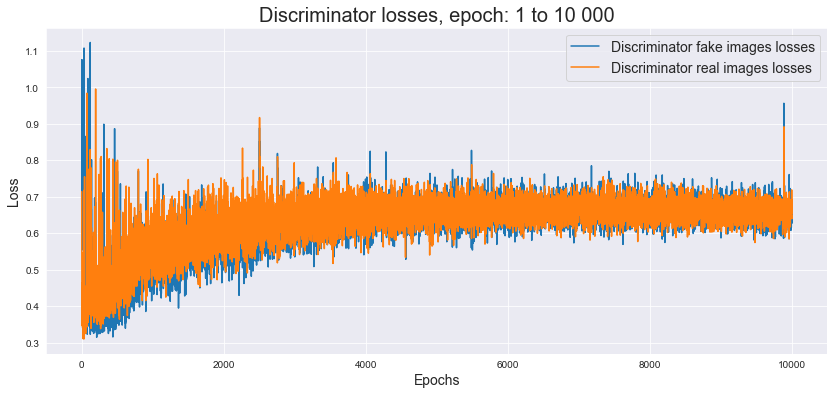
Na poniższej grafice znajdują się przykłady stworzonych przez model obrazów. Wygenerowane twarze nie pokazują perfekcyjnego odwzorowania, ale widzimy, że są to twarze ze wszystkimi właściwymi rzeczami (włosy, oczy, nos, usta) w mniej więcej odpowiednich miejscach. Można zauważyć, że sieci najtrudniej jest rysować oczy - w tym aspekcie najczęściej widać niedoskonałości. Niemniej, ogólny rezultat jest zdecydowanie zadowalający - wiele twarzy wygląda w pełni realistycznie.

Na podstawie wylosowanego szumu oraz zestawu zapisanych wag, możemy podejrzeć proces uczenia się generatora w tworzeniu coraz to lepszych obrazów. Ładnie obrazuje to poniższa grafika, na której ukazany został zestaw 6 losowych twarzy wygenerowanych co 1000 epok. Możemy zaobserwować, zadowalające kształty obrazów już w okolicy 5000 epok.

Zakończenie
Większość technologii ma świetlisty awers, ale życie dało im rewers – czarną rzeczywistość. Stanisław Lem
Sztuczna inteligencja poza wieloma korzyściami, może również przysporzyć wielu kłopotów. Przykładowo może posłużyć do: ataków hakerskich, fałszowania zdjęć, generowania fake newsów i wielu innych. Takie narzędzie jak Generative Adversarial Networks może również się temu przysłużyć. W złych rękach może być wykorzystywane do dezinformacji i propagandy oraz może podkopać zaufanie publiczne do dowodów obrazowych, co może zaszkodzić zarówno wymiarowi sprawiedliwości, jak i polityce. Wszelkie ostrzeżenia ze stron ekspertów nie powinny być ignorowane, bowiem może stać się tak, że wkrótce nie będziemy umieć powiedzieć czy coś jest prawdą, czy zwyczajnym FAKE’IEM.
Artykuł powstał na podstawie projektu Absolwenta kursu Data Science PRO.



